Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs#
2024-01
This is a good paper to cite to show that RAG is better than supervised fine-tuning (SFT). This is widely known among practitioners, but it’s good to have a source to cite.
They show that RAG performs better than SFT on a task involving answering questions from Wikipedia. RAG alone also typically performs better than RAG+SFT (tho not consistently).
They use 3 x 7B parameter models (Llama2, Mistral, Orca) to make the evaluation.
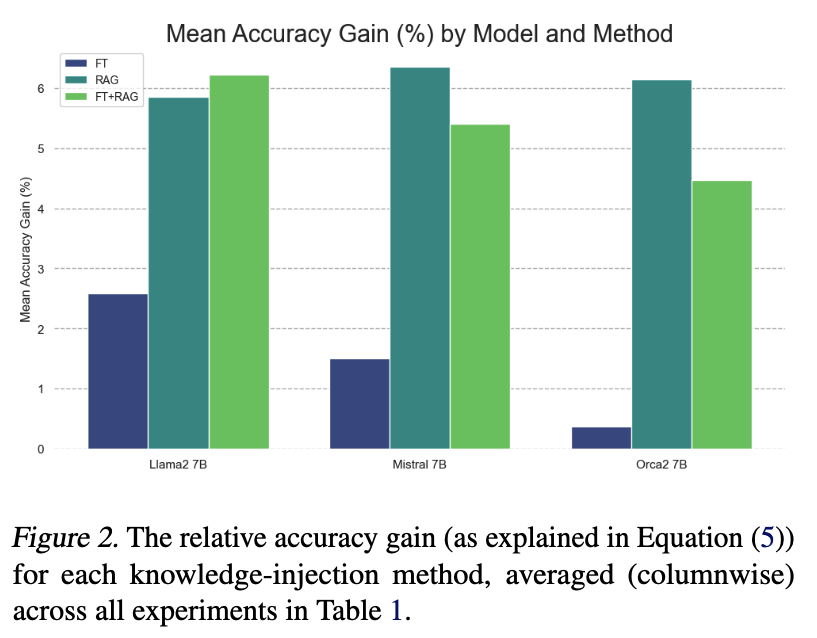
Learning vs Memorization#
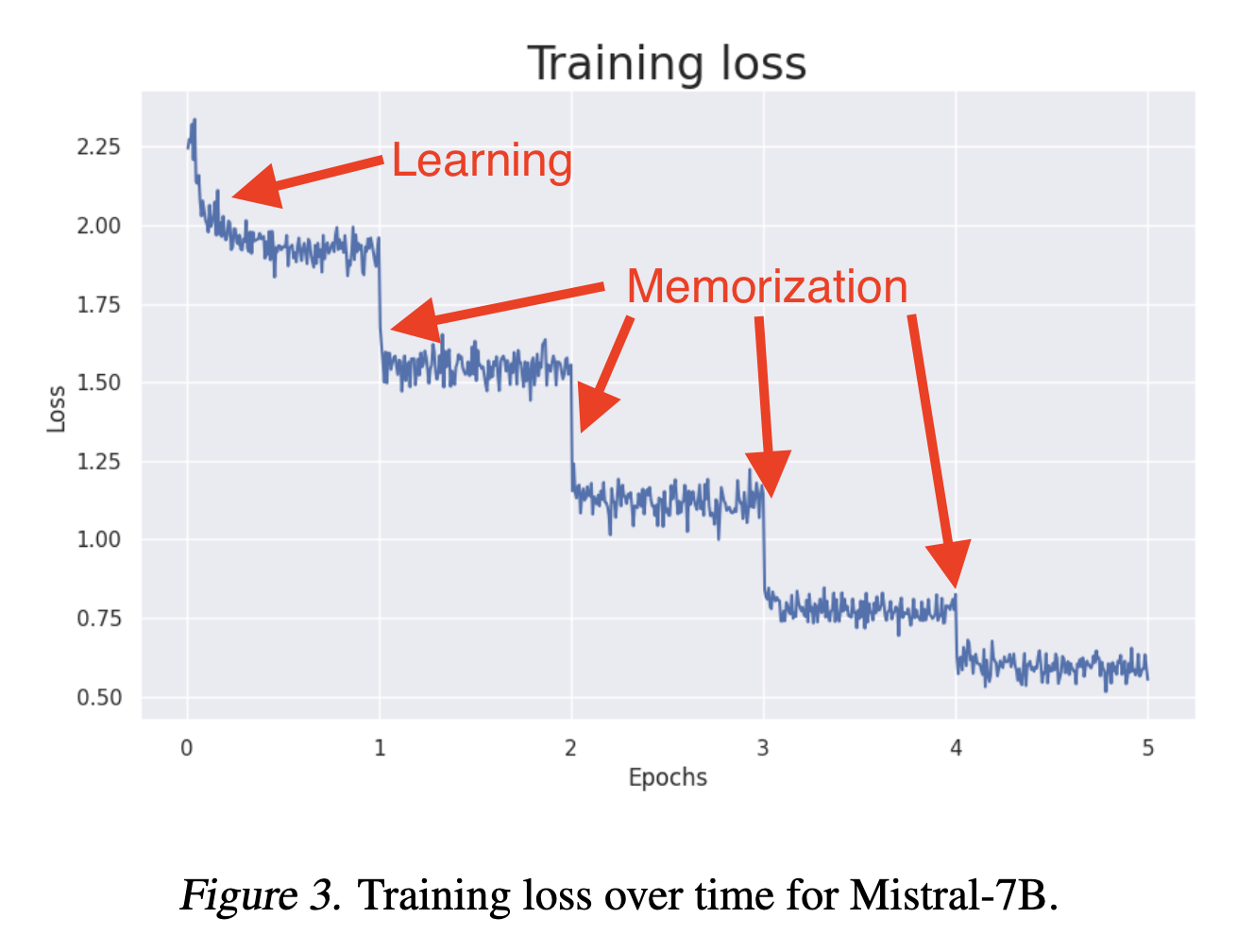
There is good evidence that Supervised Fine-tuning (SFT) is mostly memorizing the training set, rather than learning. This figure shows that learning really occurs only in the first epoch. Instead, training for multiple epochs results in sudden jumps in loss, which is consistent with training set memorization, not learning.
Information diversity during SFT#
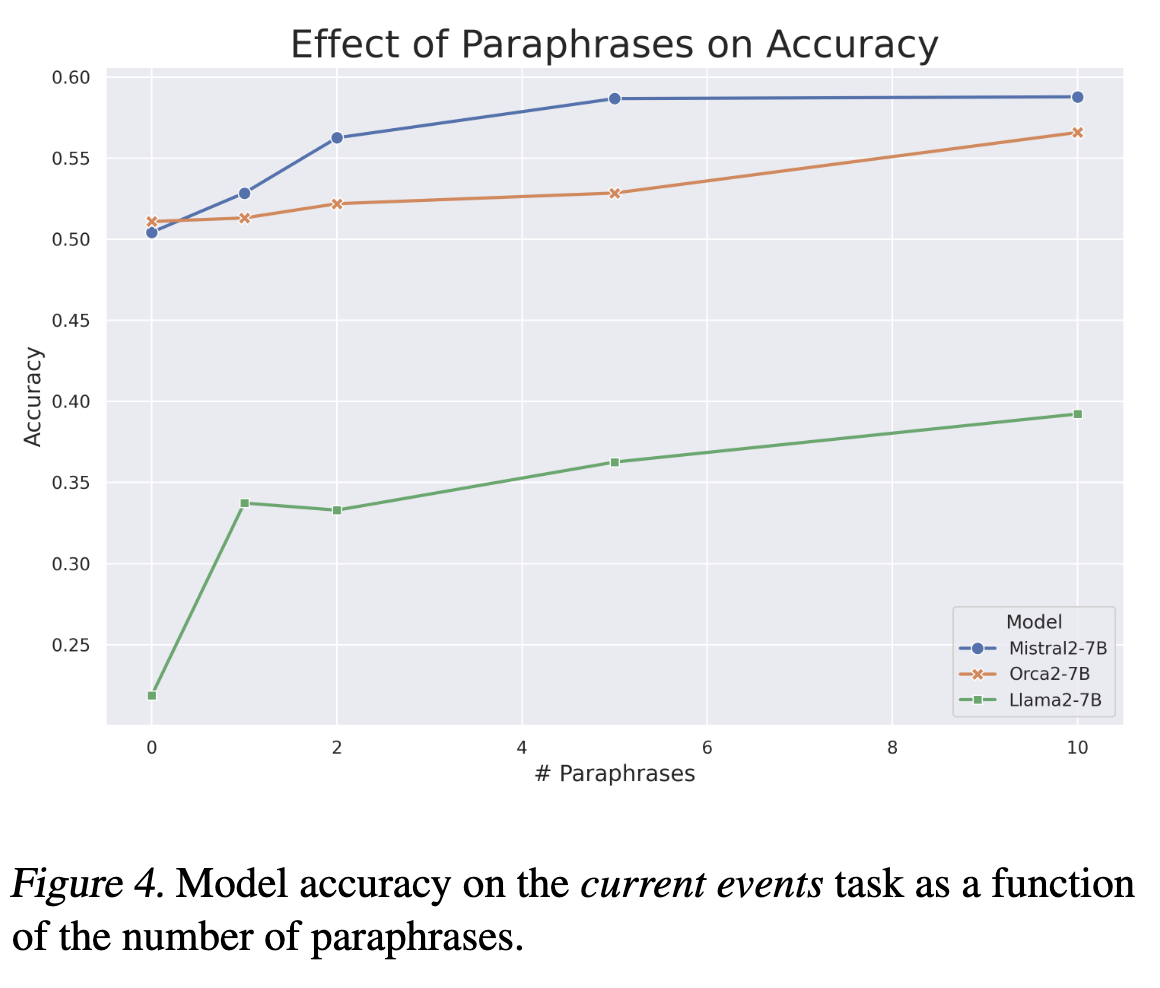
They argue that diversifying the training set (or rewording it) is a good approach. They inject paraphrases into SFT, and show that injecting more paraphrases is associated with monotonically increasing accuracy. Remember, SFT is focused only on next token prediction loss. So it can over-optimize for wording and phrasing, and under-optimize for getting the right answer (i.e., accuracy over an entire sentence or paragraph).
There has been some recent work on optimizing directly for accuracy rather than next token prediction in SFT. The Llama 3.1 Herd of Models paper kind of uses this approach when they derive a scaling law that converts the negative log loss per character into a projected accuracy on the ARC Challenge benchmark.