LLM Summarization#
Key metrics:#
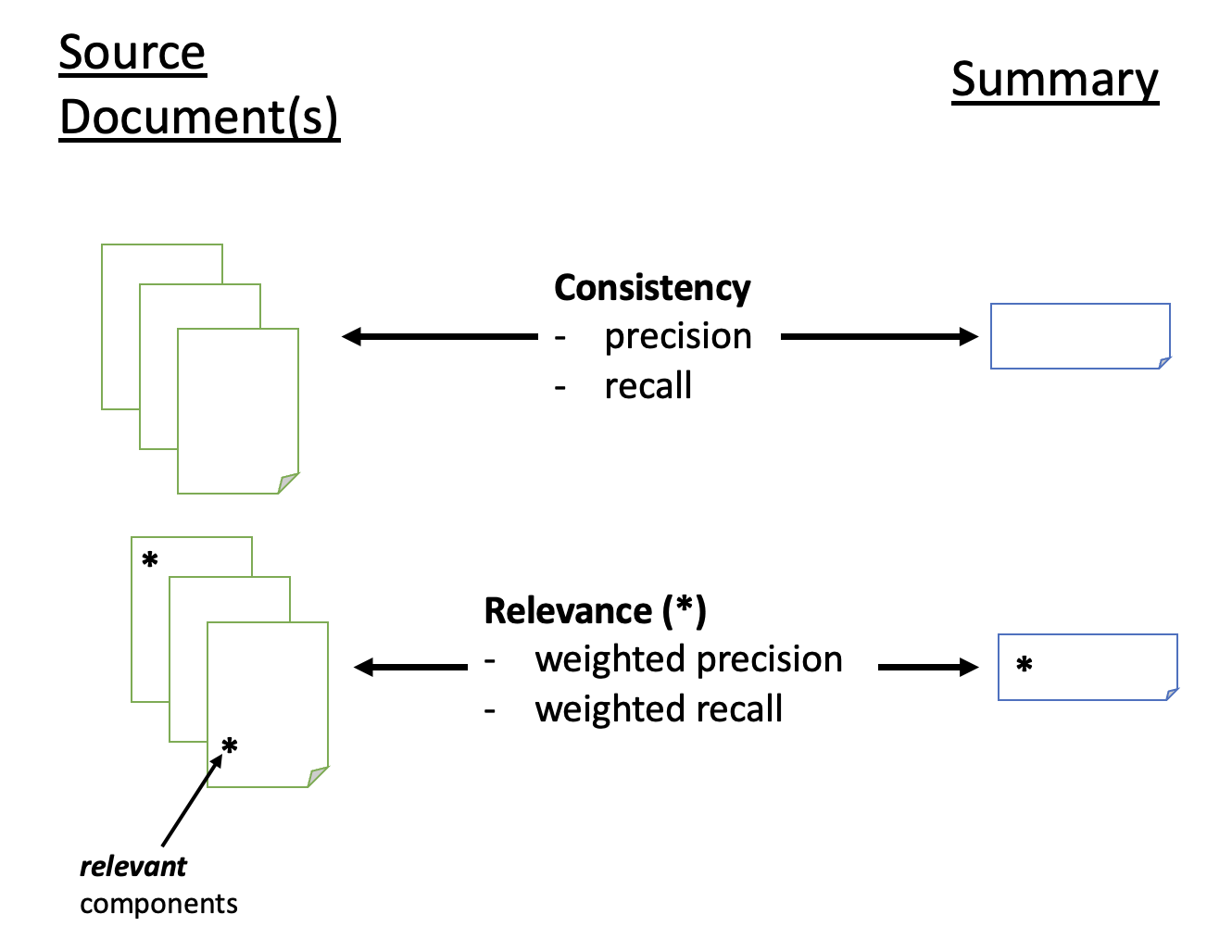
There are 3 key text strings that matter when measuring summarization: the source document(s), the generated summary, and (optionally) a ground truth summary. We care about the following metrics:
A big problem with ground truth summaries is that they are 1) expensive, and 2) often low quality. Several recent papers have shown that common summarization benchmark datasets have poor quality ground truth summaries. These include the CNN/DM (Hermann et al., 2015) and XSUM datasets (Narayan et al., 2018). Zhang (2023) found that “these benchmarks are of such poor quality that human annotators judge them to be worse than the outputs of most automatic systems”! They spent considerable resources to get experts on Upwork to generate better summaries, and they found the best LLMs (at the time, GPT-3) were comparable to Upwork quality from the perspective of human feedback.
In the absence of high quality ground truth data, most metrics are computed on the basis of the source document(s) and the generated summary. These include:
Consistency: Does the summary accurately capture the main ideas in the source document(s)? Consistency has 2 components: precision and recall. For precision, there should be no hallucinations, where the summary adds information not present in the source document. For recall, the summary should capture all – or as many as possible – of the main ideas in the source document(s).
Relevance: Does the summary pay attention to the most important aspects of the source document? Does it ignore irrelevant information? At first blush, relevance doesn’t seem very different from consistency. You can think of relevance as a kind of weighted precision and recall. Where consistency makes sure that all parts of the summary and source document(s) match, relevance makes sure the important parts do. Where consistency can be computed directly from the summary and source documents(s), relevance includes aspects of human feedback. A key point is that relevance may differ from user to user, whereas consistency does not. How do we get signals about relevance? Sometimes the source documents have information that we can upweight. For example, if we’re summarizing Tweets, we might pay attention to source documents with higher likes, bookmarks, retweets, and impressions. If we’re summarizing journal articles, the centrality of the article in the literature or the prominence of the journal could help. Other times, we can only rely on human feedback to the generated summaries themselves. This is where Reinforcement Learning with Human Feedback (RLHF) becomes important.
Other metrics that we used to pay attention to, but don’t matter with LLMs (b/c LLMs almost always do well on them):
Coherence and Fluency: The summary should be written in clear language, without mispellings, typos, and free of logical errors. Most LLMs can do this easily, so it’s not useful to evaluate on this basis.
See Kryscinski et al. (2019) for the original proposal on these metrics.
Measuring Precision#
Precision can be measured using a Natural Language Interface (NLI) model finetuned on your task. The standard NLI task is to check entailment from a premise. For example, given the following 2 premises:
Premise: All humans are mortals.
Premise: Socrates is a human.
The then model evaluates if the following hypothesis/statement is logically entailed:
Entailment?: Socrates is mortal.
Typically, the model is trained to distinguish 3 categories:
entailment: the statement logically flows from the premises.
contradiction: the statement logically violates the premises.
neutral: the statement is neither entailed nor contradicted by the premises.
The trick in NLI for summarization is to use the source document(s) as the premise and the generated summary as the hypothesis.